深度学习
语义分割和目标检测 (Semantic Segmentation and Object Detection)
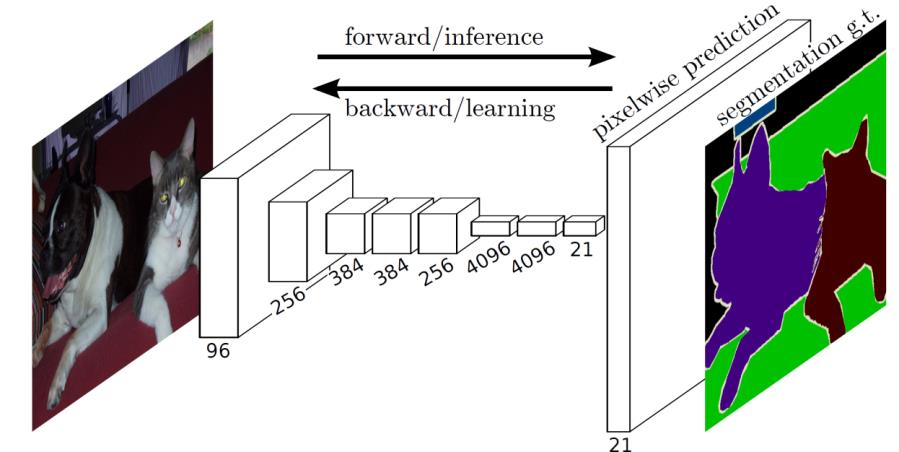
场景标注 Scene Labeling
分割图像
- 分类每个像素
- 自动编码器/解码器结构

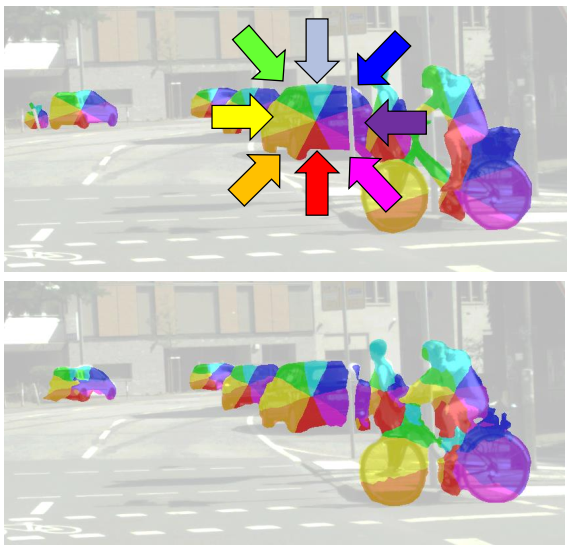
实例标签 Instance Labeling
语义标签不提供对象边界!

想法:将方向标记为对象中心

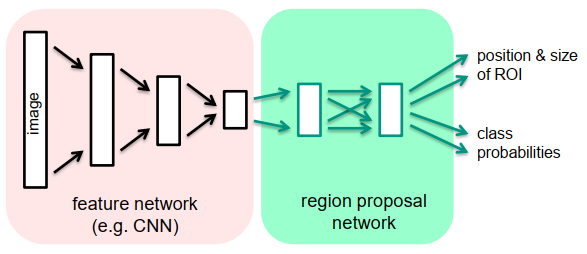
区域生成网络Region Proposal Networks
Region Proposal Network,直接翻译是“区域生成网络”,通俗讲是“筛选出可能会有目标的框”。其本质是基于滑窗的无类别object检测器,输入是任意尺度的图像,输出是一系列矩形候选区域。


我们在哪里可以找到哪些对象?
- 将图像划分为单元
- 在每个单元中应用区域生成网络
- 改变划分的单元大小以处理更大/更小的对象
深度学习技术
没有比更多数据更重要的数据了!
-
训练过程的严格验证
-
训练过程的正则化
-
– 提前停止
-
– 权重衰减/L2 正则化
-
– dropout
-
– 随机梯度下降
-
– 多任务学习
-
– 使用预训练网络
-
– 损失函数
-
-
重用 (他人的)实践知识
-
– 成功的网络结构
-
– 成功的培训过程
训练期间的典型错误进展

为什么早期停止作为正则化技术起作用?
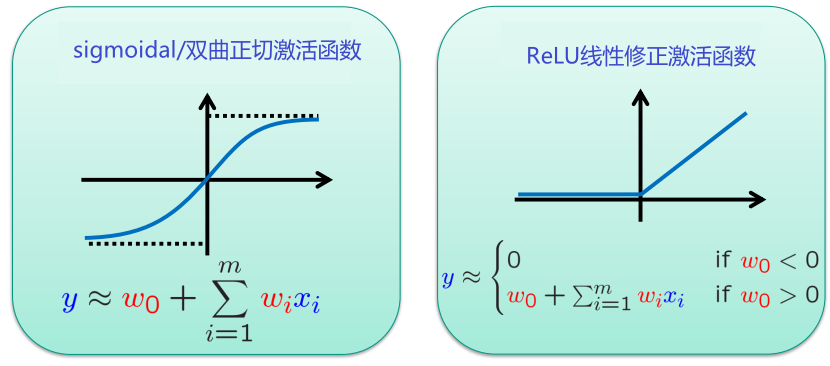
- 提前停止更倾向小权重
- 小权重意味着几乎没有非线性
小权重正则化
假设感知器的绝对权重较小
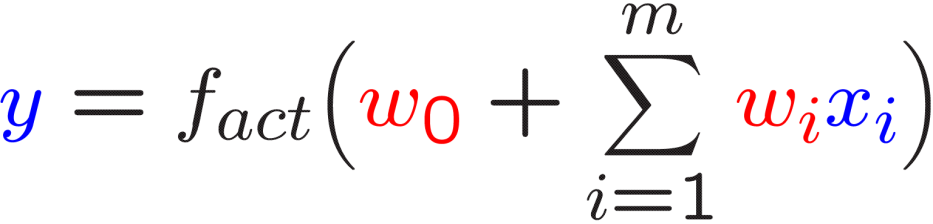
小权重促进感知器的线性行为
假设具有线性激活的全连接网络
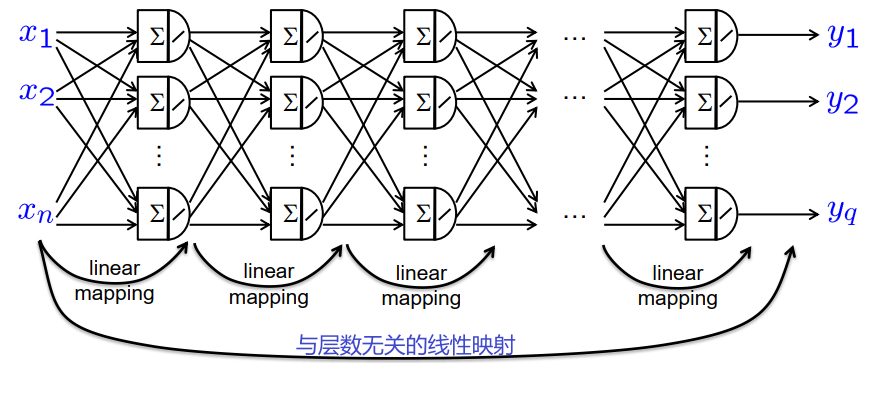
→感知器的线性行为降低了非线性表达性
→正则化
权重衰减/L2-正则化 Weight Decay / L2-Regularisation
通过正则化规则扩大训练目标

通过在训练期间随机关闭感知器进行正则化
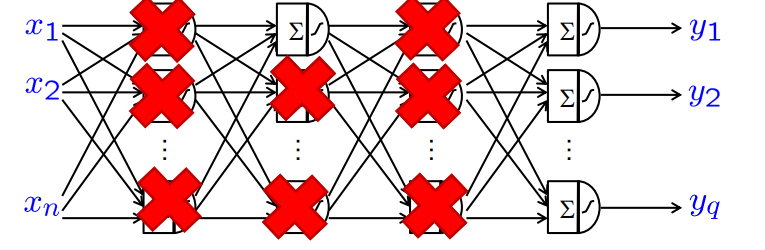
dropout 迫使神经网络以分布式方式存储相关信息
dropout 减少过拟合
梯度下降的修正
随机梯度下降
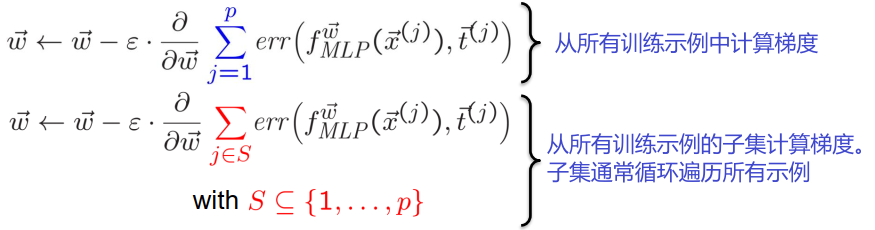
优点:
- 加速
- 减少一点过拟合
动量梯度下降
\[\begin{aligned} \Delta \vec{w} & \leftarrow \alpha \cdot \Delta \vec{w}-\varepsilon \cdot \frac{\partial}{\partial \vec{w}} \sum_{j \in S} \operatorname{err}\left(f_{M L P}^{\vec{w}}\left(\vec{x}^{(j)}\right), \vec{t}^{(j)}\right) \\ \vec{w} \leftarrow \vec{w}+\Delta \vec{w} \end{aligned}\]用一个α>0参数来控制后续步骤的一致性
优点:
- 在平坦区域加速
- 减少曲折
多任务学习 Multi Task Learning
想法:在单个网络示例中学习多个相关任务:
场景标记+实例标记+深度估计
scene labeling + instance labeling + depth estimation
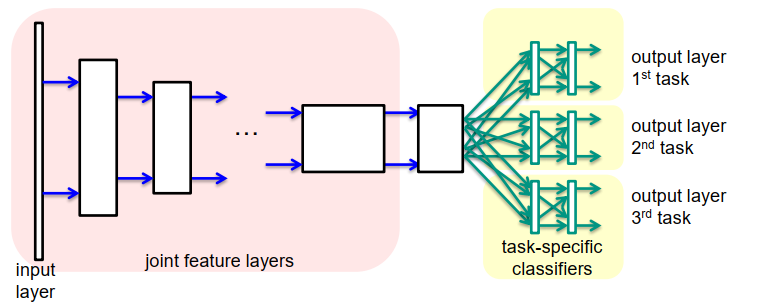
优点:
- 强制网络在隐藏层中开发共同特征
- 减少对单个任务的过度拟合
预训练特征网络的使用
想法:重用预训练的网络
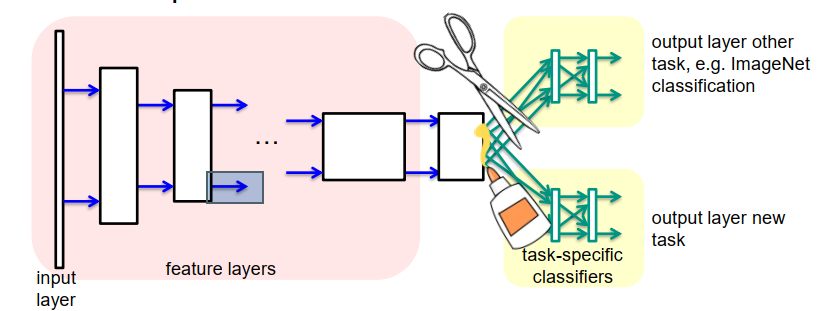
- 用大型训练集训练其他任务
- 丢弃其他任务的分类层
- 为新任务创建新的分类层
- 训练新分类层的权重,同时保留特征层
输出层和损失函数 Output Layers and Loss Functions
损失函数将网络输出与期望的输出进行比较

-
情况(回归任务):期望的输出应该是实数
-
在输出层使用线性激活函数
-
使用平方误差,即
-
-
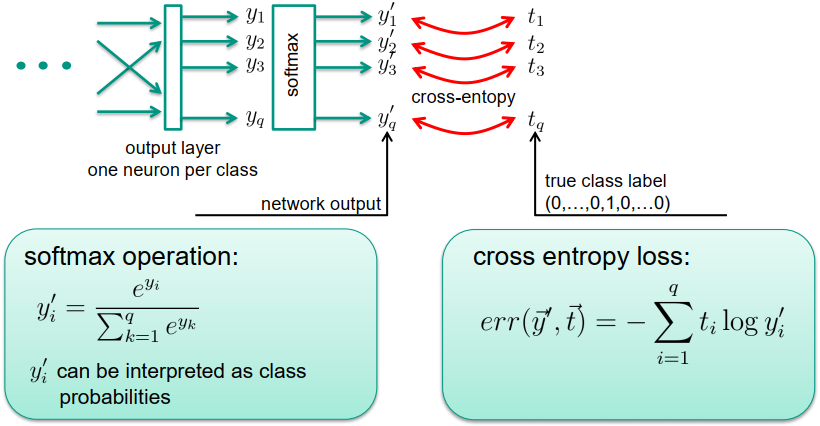
情况(分类任务):期望的输出应该是类别标签
-
在输出层使用softmax激活函数
-
使用交叉熵误差 cross entropy error
-
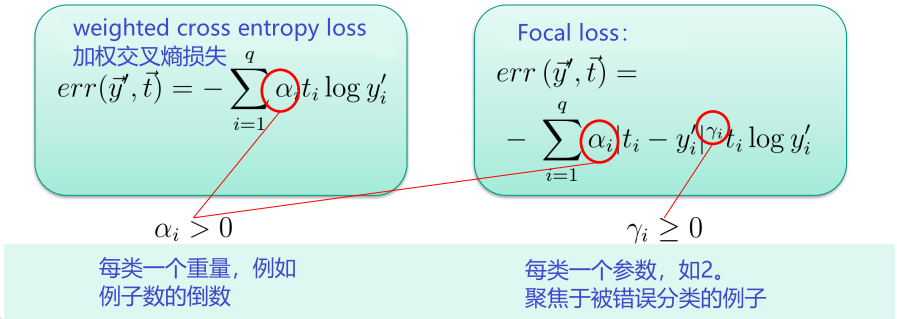
不平衡训练集的变体
对于严重不平衡的训练集(即每个类的示例数量不相等),训练可能会失败
引入加权因子来补偿不平衡
来自深度学习工具箱的其他技术
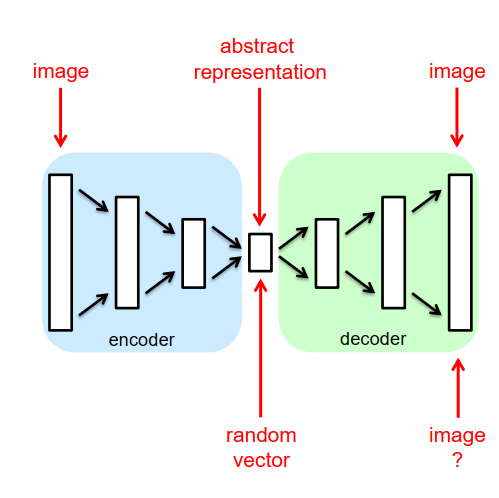
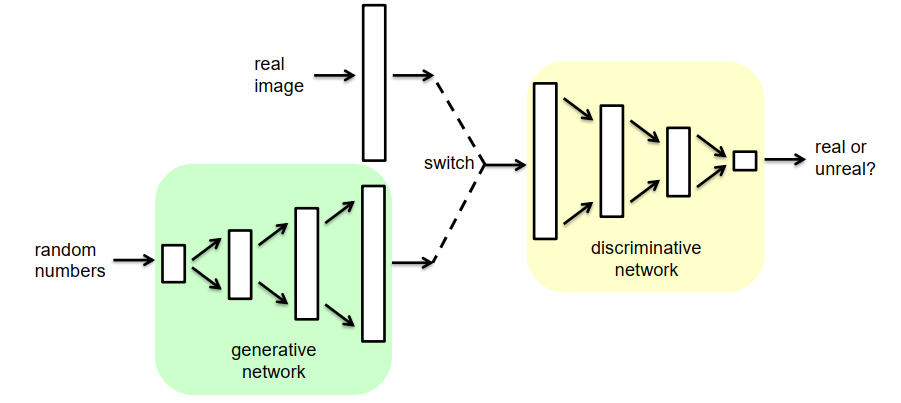
生成对抗网络 (GAN) Generative Adversarial Networks (GAN)
我们可以使用深度网络生成逼真的图像吗?
-
生成网络应该学会生成逼真的图像
- 鉴别性网络应该学习如何区分图像是真实的还是生成的。
- 训练:两个网络都是零和游戏中的竞争对手
应用领域: • 图像渲染 • 域适应 • 为分类器生成(附加)训练数据
序列处理Sequence Processing
我们如何处理序列,例如 视频序列?
(1) 多通道输入层
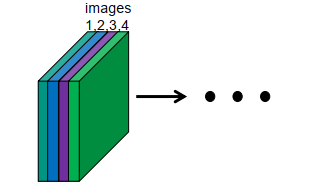
只有在以下情况下才有可能
- 短序列
- 固定长度的序列
(2)图像单独处理+拼接层
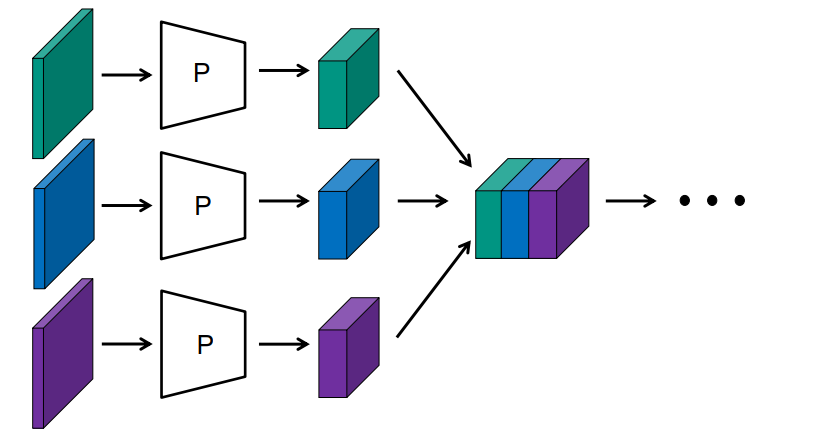
只有当
- 短序列
- 固定长度的序列
(3) 图像的单独处理+附加层(深度集)
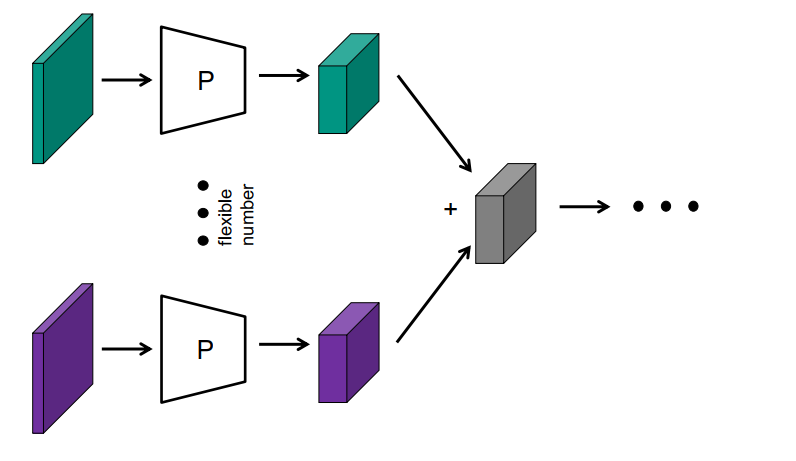
只有当
- 图像的顺序并不重要
(4)递归网络
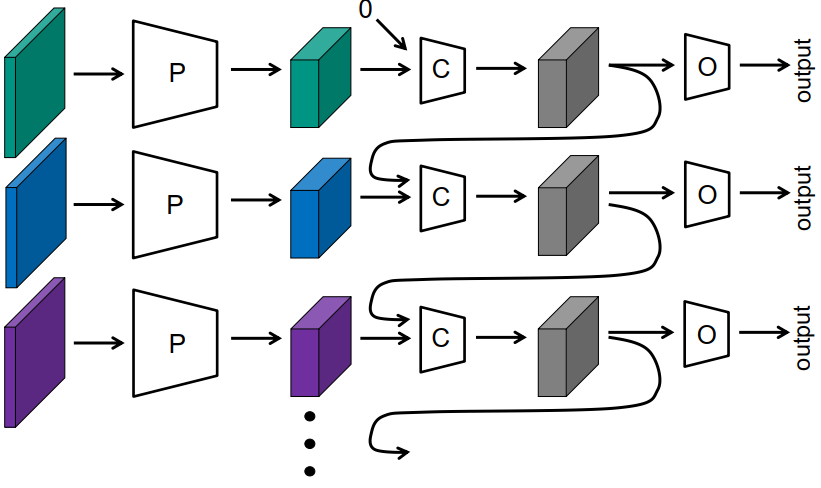
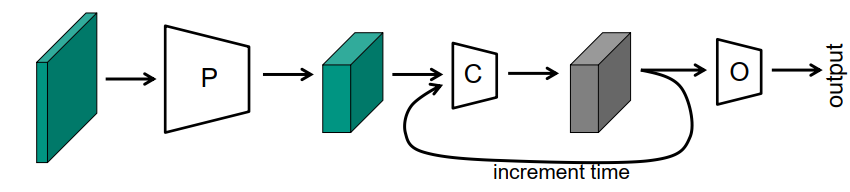
-
学习算法:通过时间进行反向传播
- 问题:梯度消失
- 解决方案:用适当的处理单元(GRU、LSTM)取代网络C中的感知器。 适当的处理单元(GRU, LSTM)
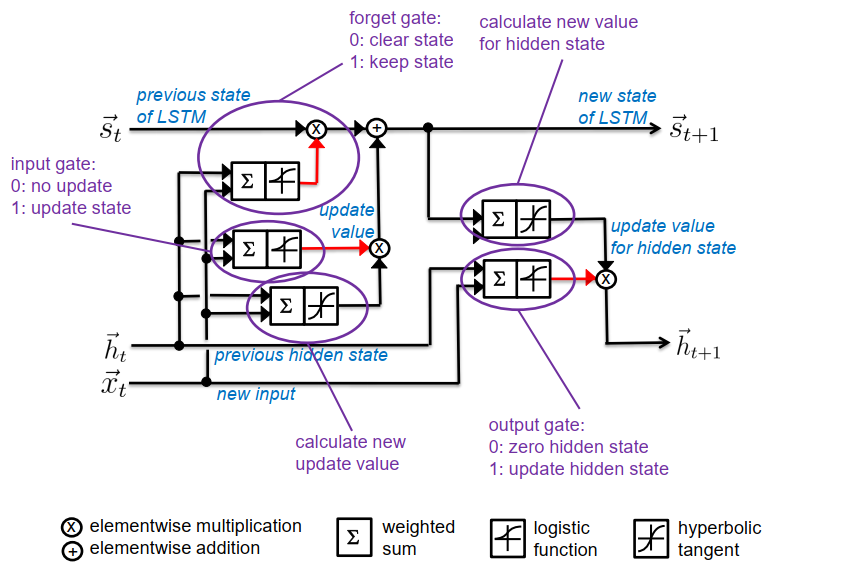
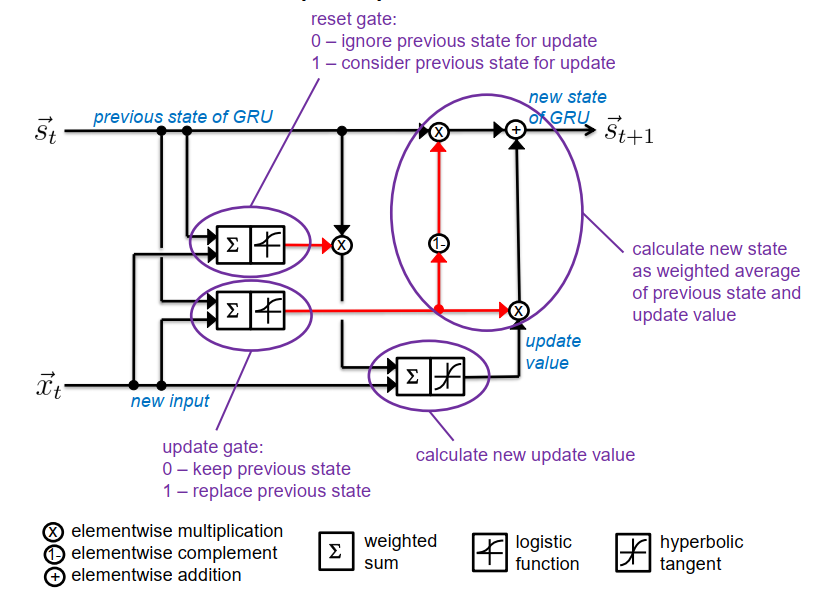
循环单元 (GRU+LSTM) Recurrent Units (GRU+LSTM)
-
实现简单状态机的专用单元
- 状态从不通过双曲切线的逻辑函数→来传递 没有消失的梯度
- 内部结构有几个控制信息流的闸门
- 使用感知器机制打开/关闭闸门
- LSTM:更早(1997年),更复杂(需要5个感知器)。
- GRU:较新(2014年),门数较少,参数较少(需要3个感知器)。
门控循环单元 (GRU)
长短期记忆单元 (LSTM)